如果一个人把自己的记忆弄丢了,那人生只是一个单纯的奔向死亡的过程,无论在他人眼中是什么样的存在,终究是一副空壳而已。而无论那记忆是美好,痛苦或是平淡,那都是我们生命中的一部分,无法割舍的深深的烙印。
# 效果图展示
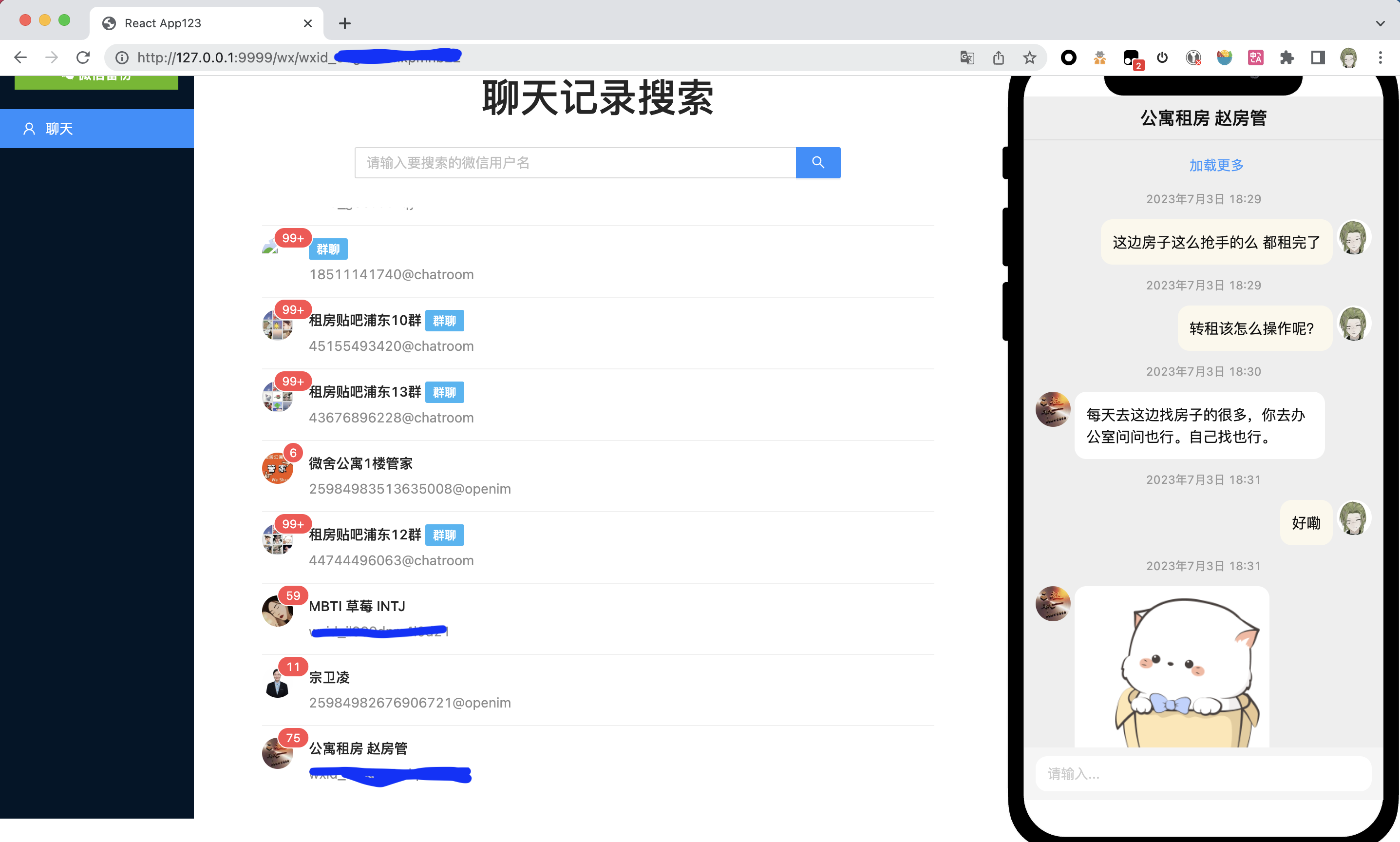
- wechat-backup 导出
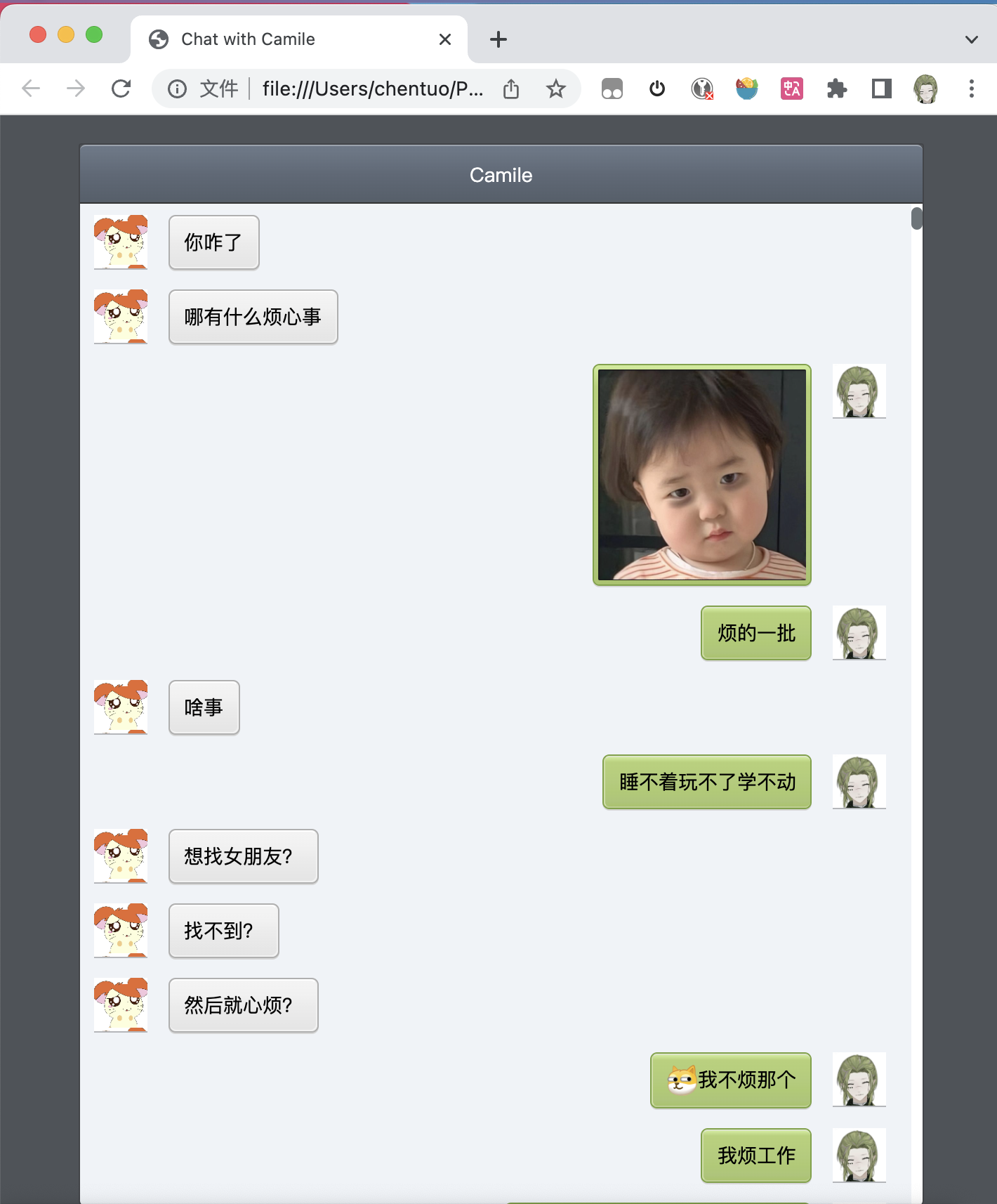
- wechat-dump 导出
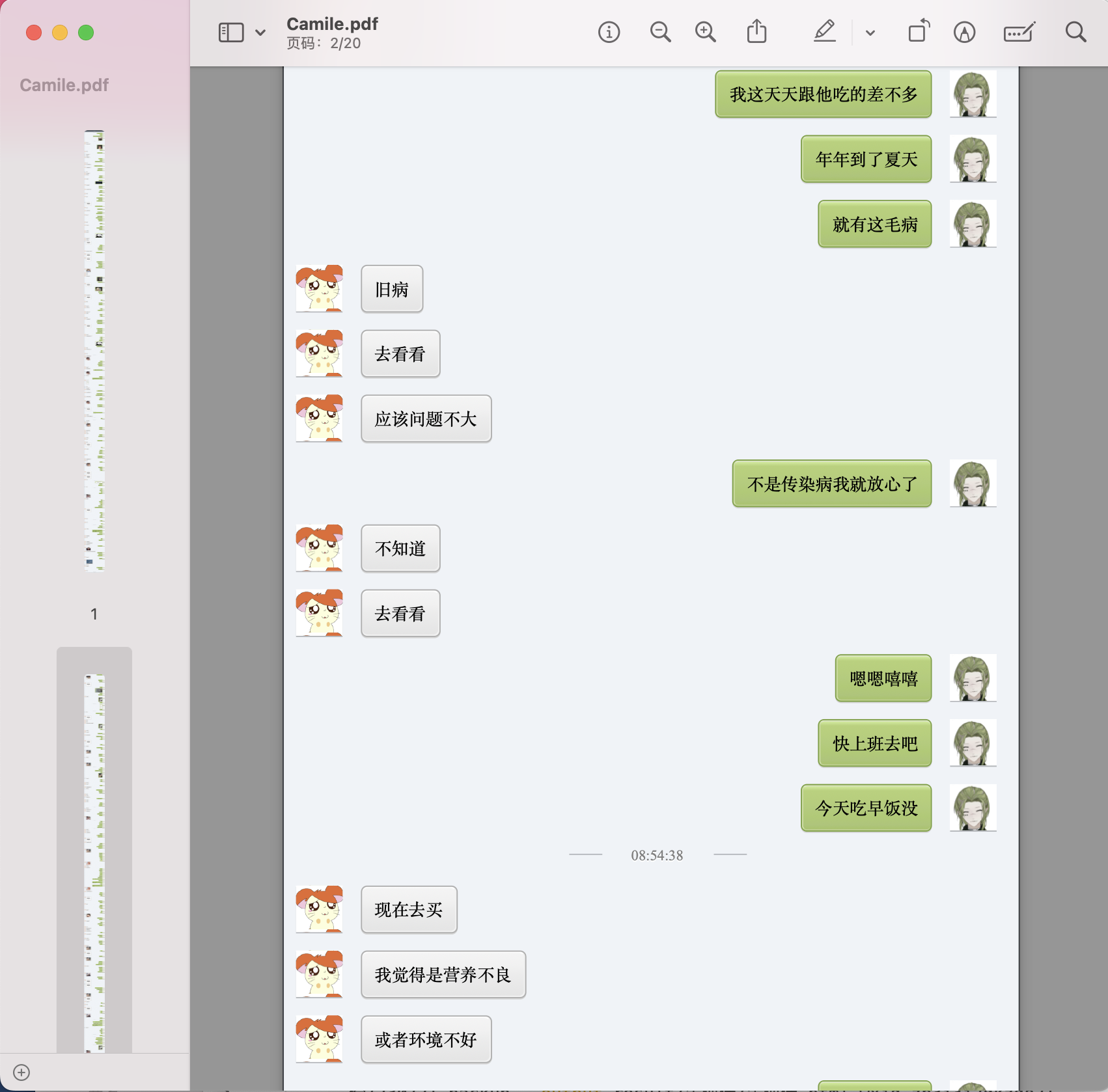
- 聊天记录转 pdf
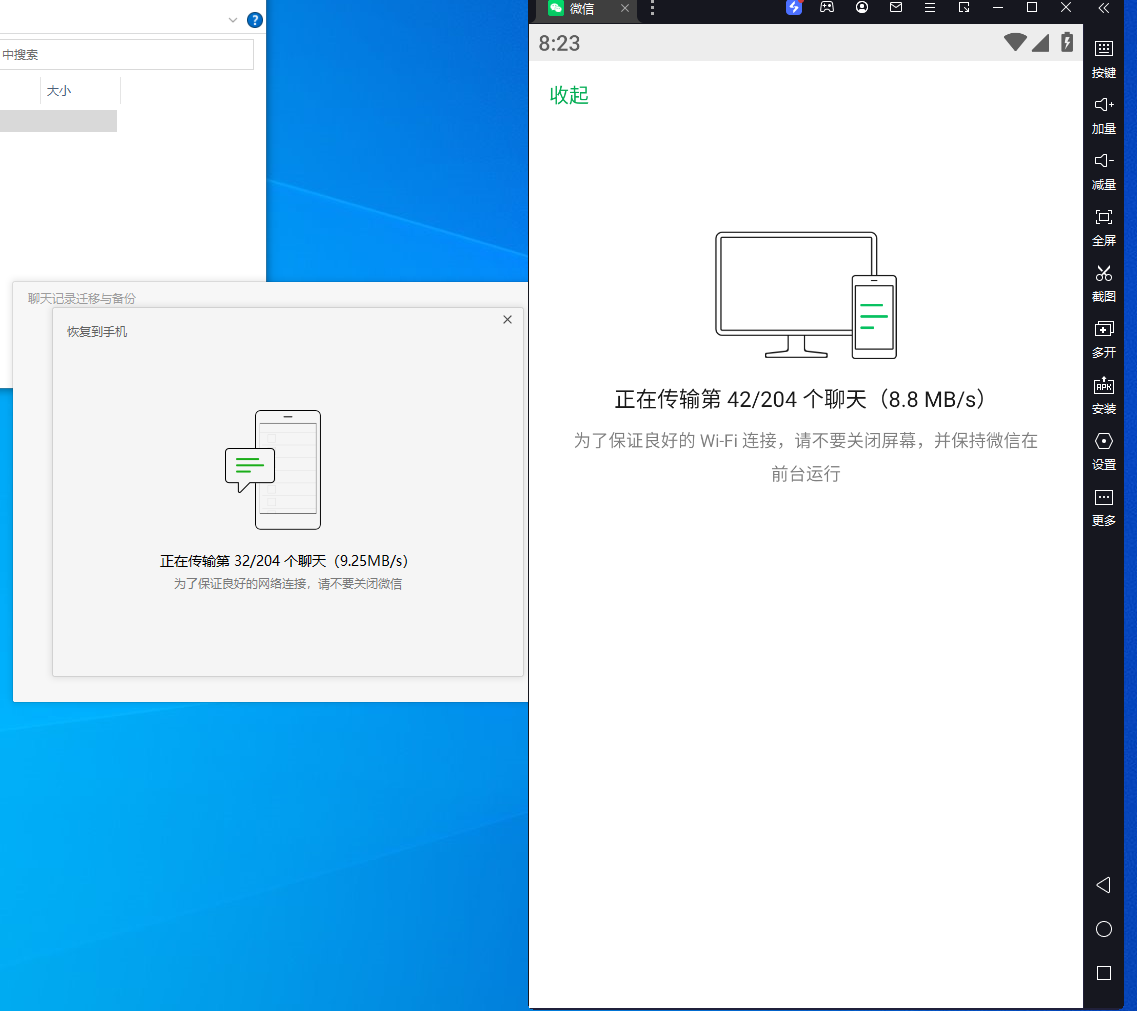
# 聊天记录转移至模拟器
手机聊天记录备份至电脑 -> 电脑聊天记录备份至模拟器 -> 雷电模拟器开启 root -> 模拟器下载 ES 文件浏览器并启用 root 工具箱 -> 复制微信数据库等资料到共享文件
-
手机聊天记录备份至电脑后,将电脑上存储的聊天记录备份至电脑上的安卓模拟器
![Image]()
-
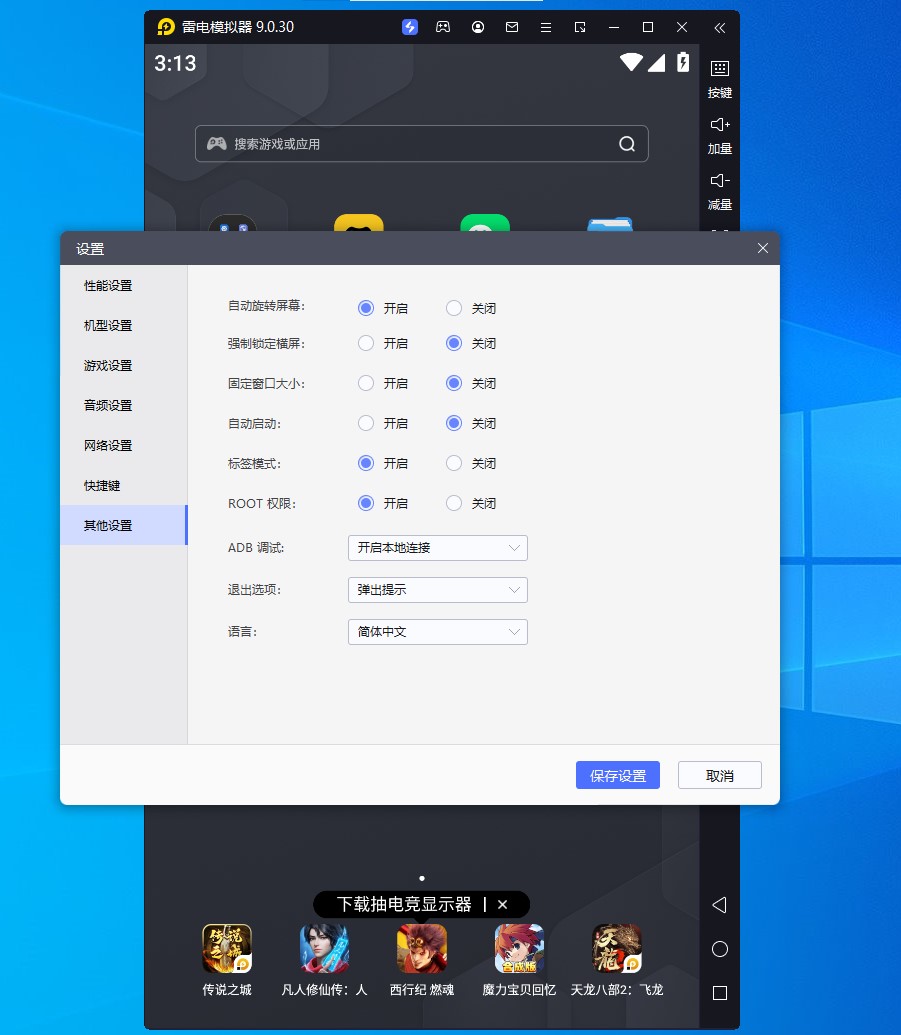
这里我用的是雷电模拟器,在设置里边可以直接开启 root 权限
![Image]()
-
模拟器安装 ES 文件浏览器,通过此文件管理工具操作文件
![Image]()
-
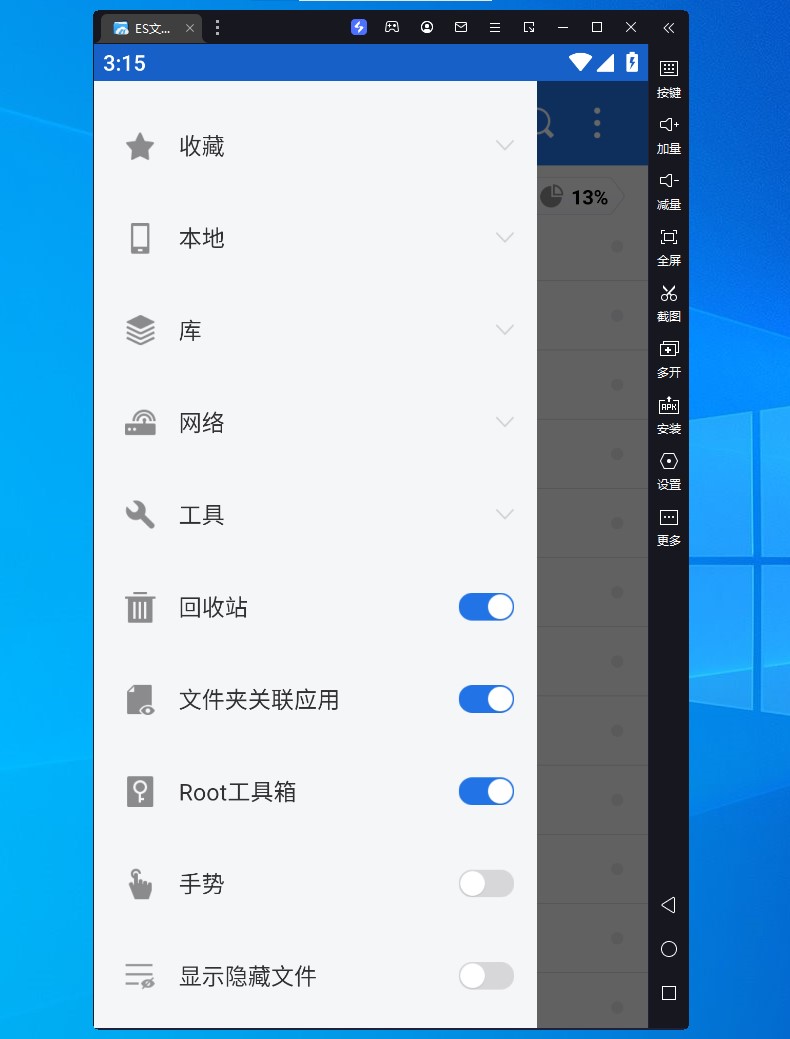
ES 文件浏览器开启 Root 工具箱
![Image]()
-
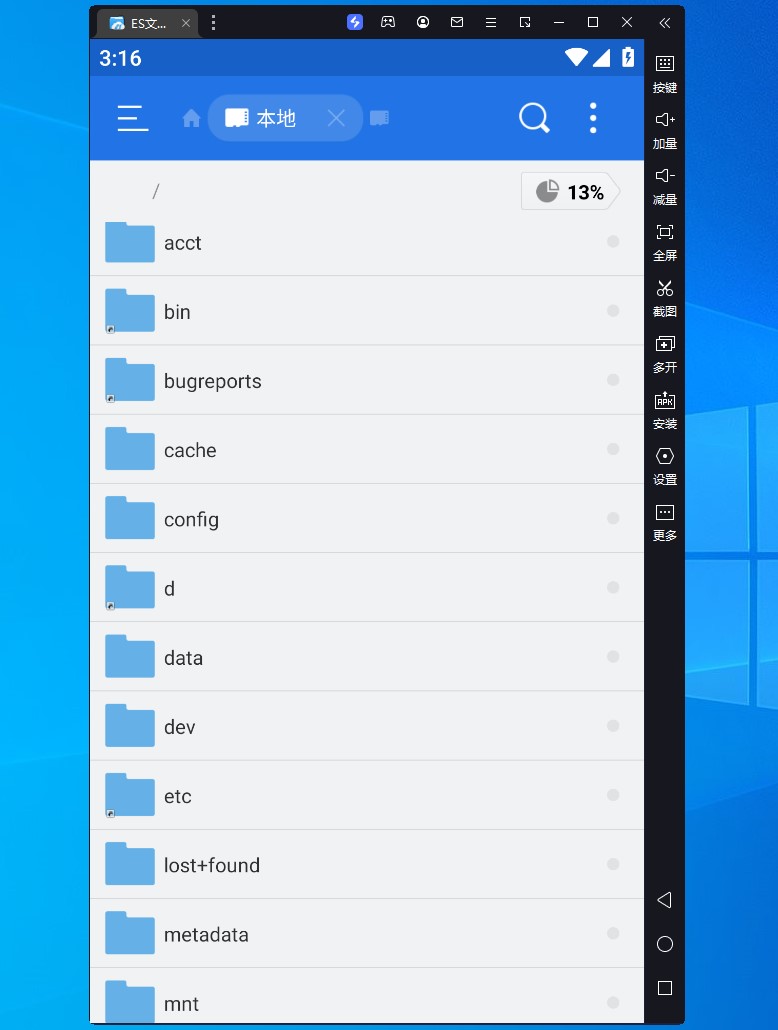
此时已经有权限可以看到安卓模拟器上的所有文件夹及文件
![Image]()
# 收集微信相关数据
各文件夹具体作用参考文章:https://blog.greycode.top/posts/android-wechat-bak/
收集以下数据:
auth_info_key_prefs.xml uin 位置:/data/data/com.tencent.mm/shared_prefs/auth_info_key_prefs.xml
image2 所有的微信聊天图片:/data/data/com.tencent.mm/MicroMsg/[32 位字母]/image2
voice2 所有的微信语音:/sdcard/Android/data/com.tencent.mm/MicroMsg/[32 位字母]/voice2
voide 所有的微信视频:/sdcard/Android/data/com.tencent.mm/MicroMsg/[32 位字母]/voide
avatar 所有的微信头像:/data/data/com.tencent.mm/MicroMsg/[32 位字母]/avatar
Download 聊天发送的文件存放在这里:/sdcard/Android/data/com.tencent.mm/MicroMsg/Download
EnMicroMsg.db 微信数据库文件:/data/data/com.tencent.mm/MicroMsg/[32 位字母]/EnMicroMsg.db
WxFileIndex.db 文件索引:/data/data/com.tencent.mm/MicroMsg/[32 位字母]/WxFileIndex.db
emoji 表情包:/data/data/com.tencent.mm/MicroMsg/emoji
-
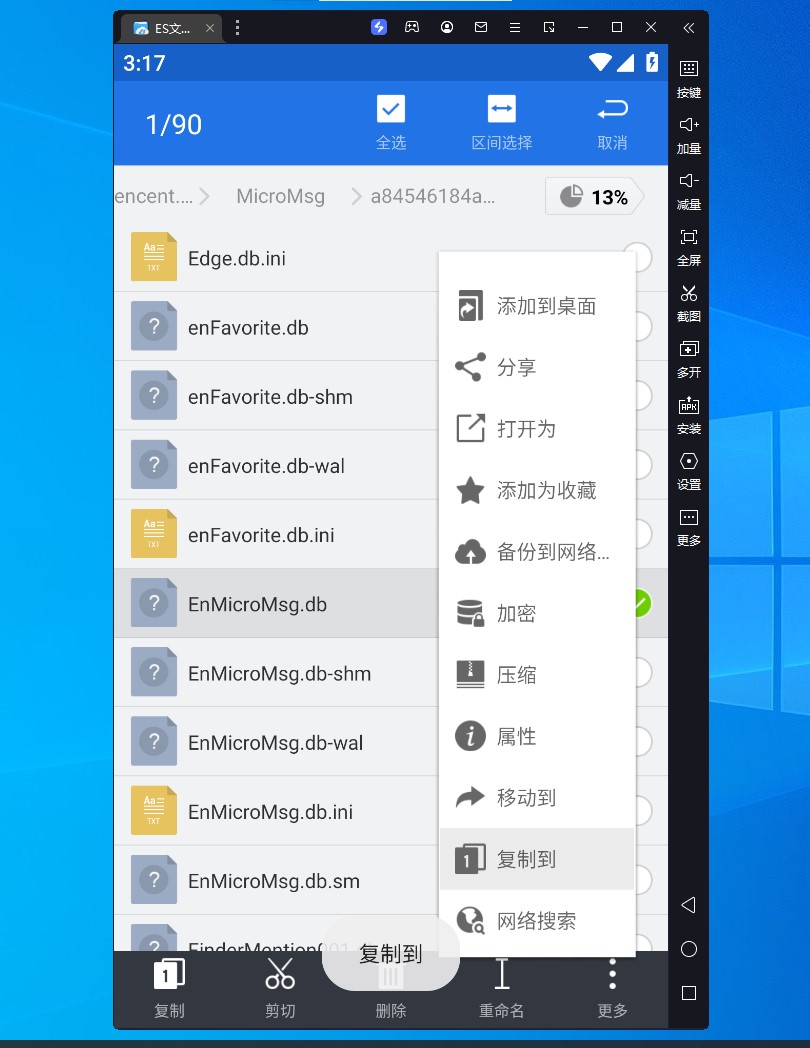
收集数据,以微信本地数据库 EnMicroMsg.db 为例,长按 -> 更多 -> 复制到
![Image]()
-
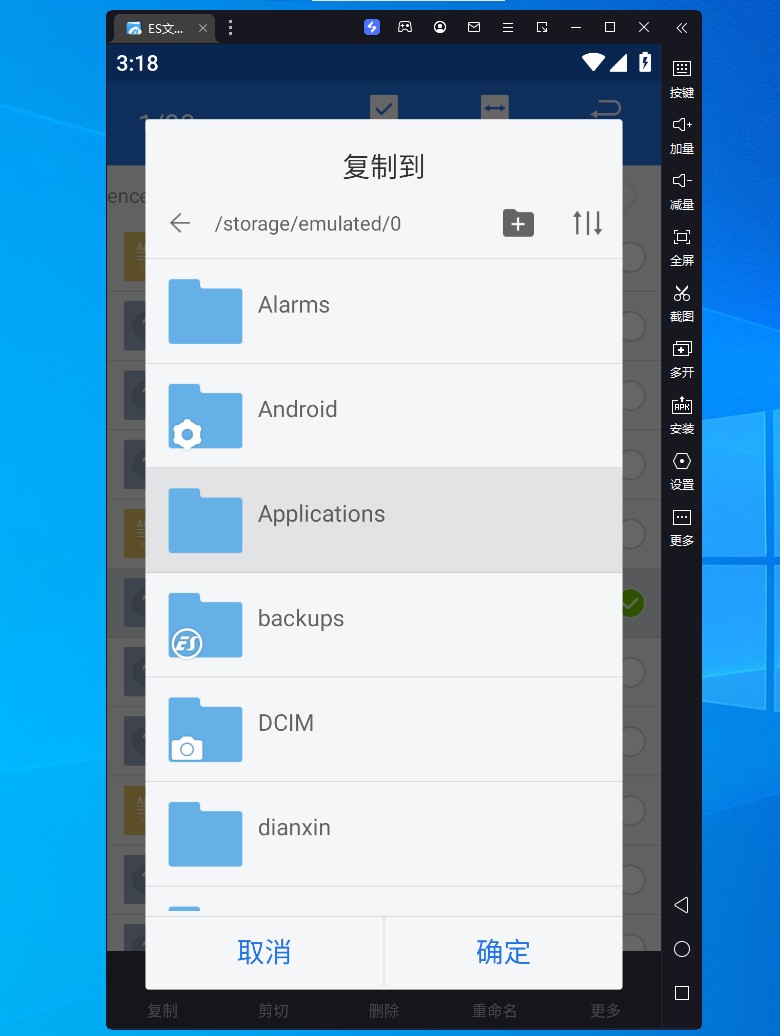
我选择了复制到 Applications 的共享文件,也可以选择 Alarms 及 dianxin
![Image]()
-
如果觉得传输速度太慢,可以先压缩,再复制过去解压
![Image]()
-
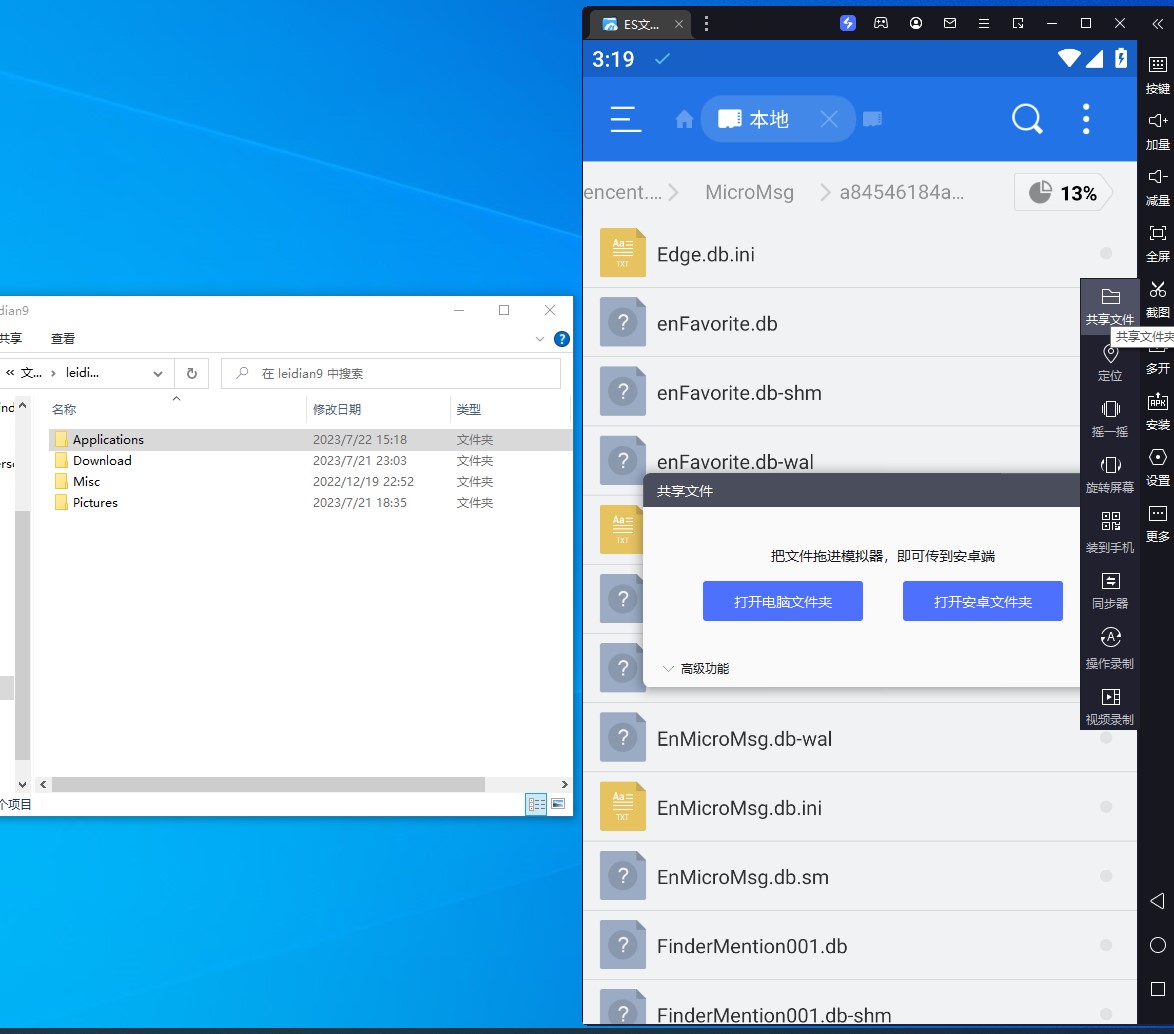
打开模拟器的共享在电脑上的文件夹的位置,判断复制成功
![Image]()
-
同样的方法,复制其他需要收集的数据到电脑上的共享文件中
![Image]()


# 数据前期处理
数据库解密参考文章:https://blog.csdn.net/sinat_25926481/article/details/122326313
音频解码参考文章:https://github.com/greycodee/wechat-backup
获取数据库密码 -> 解密微信数据库 -> 解码音频文件
- 获取 uin 值,如图 _auth_uin 所在行的值就是,我的为 - 1639125062
微信数据库密码为 IMEI+UNI 的 md5 加密后的前 7 位
IMEI+UNI:1234567890ABCDEF-1639125062
在线 md5 加密: https://md5jiami.bmcx.com/
命令行 md5 加密:echo -n “1234567890ABCDEF-1639125062” | md5
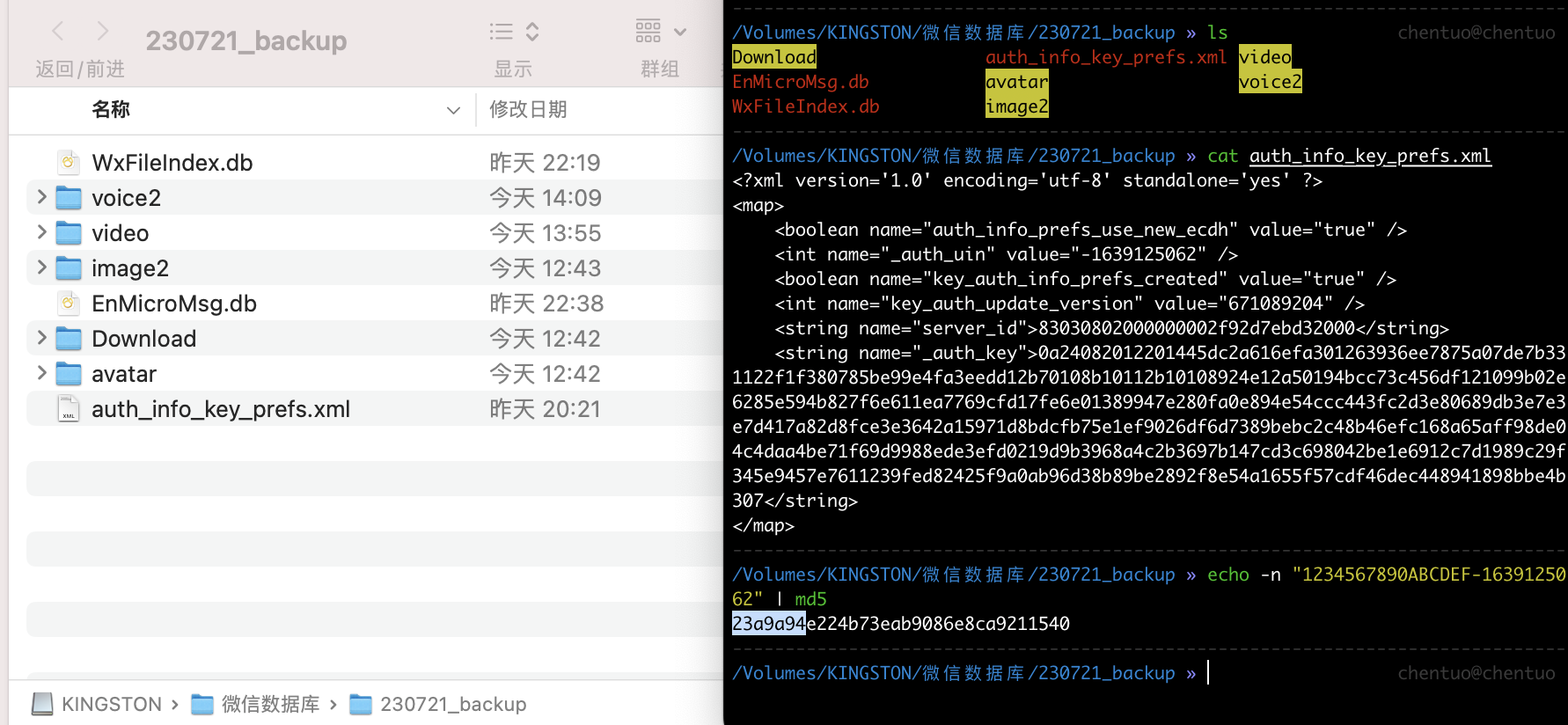
如图,显示的前 7 位为我的数据库密码:23a9a94
- 通过获取到的数据库密码将 EnMicroMsg.db 导出为一个未加密的数据库,依次输入以下命令解密数据库
1 | 安装sqlcipher -> 如果系统是os,请根据参考文章给出的方式安装工具 |
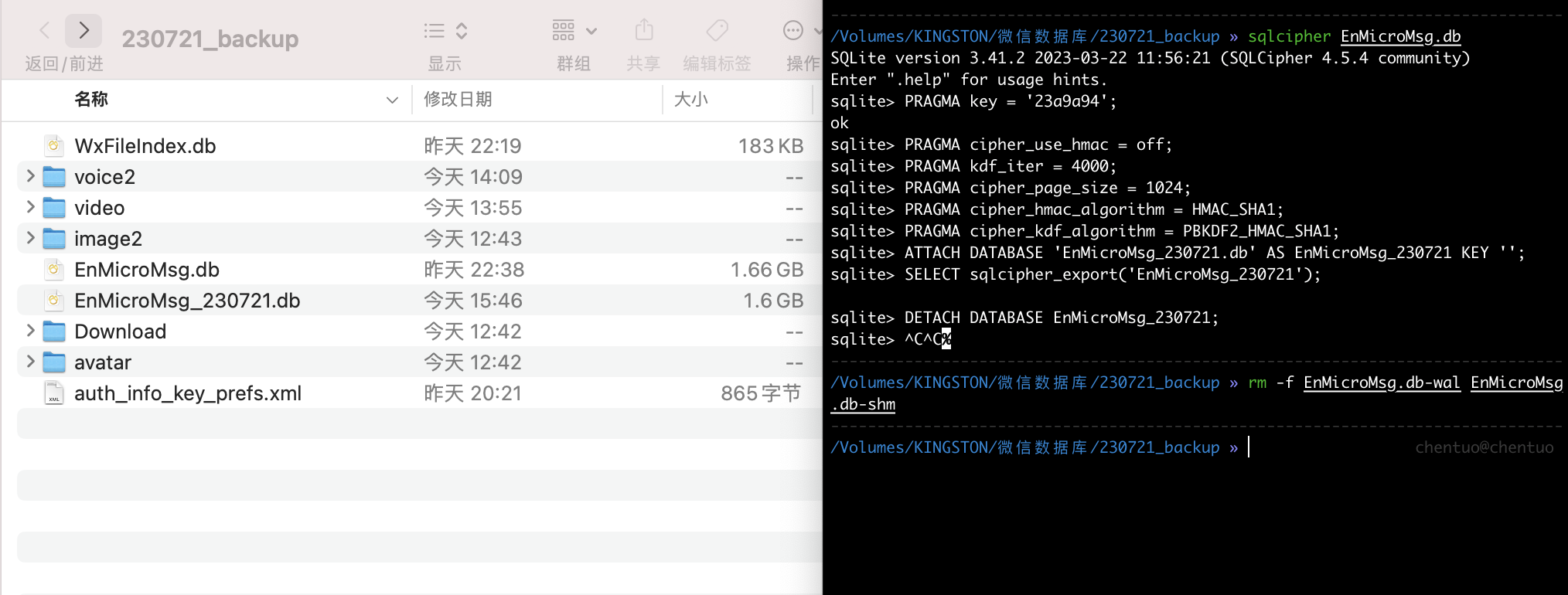
如图,将导出为一个未加密的数据库,名为 EnMicroMsg_230721.db
-
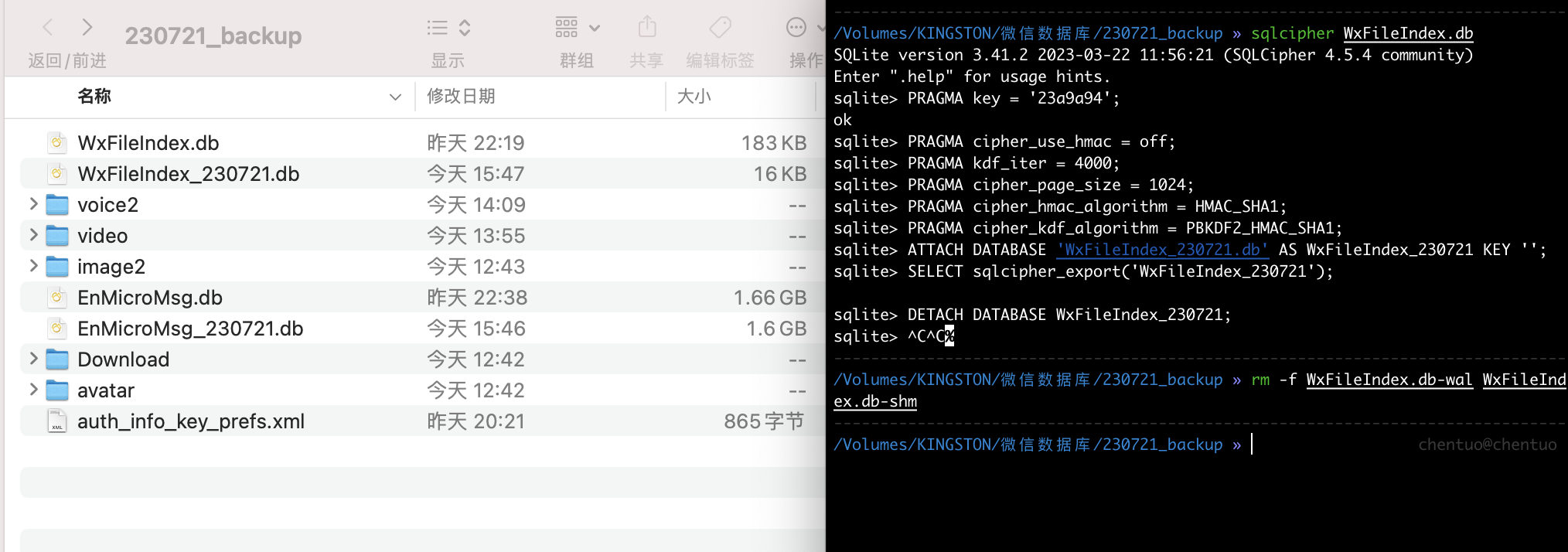
同样的方法,解密微信索引数据库 WxFileIndex.db, 注意导出的数据库名字不可以重复
![Image]()
-
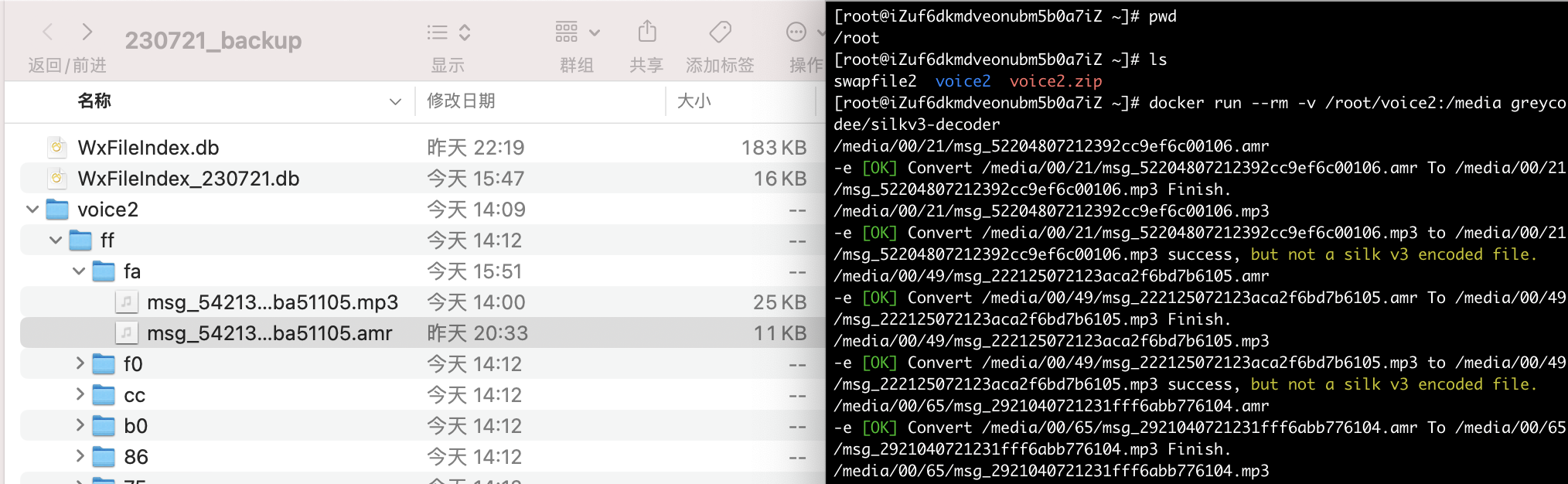
通过 docker 拉取 greycodee/silkv3-decoder 镜像,将编码后的 amr 格式解码为 mp3
1 | 我将 voice 发送到了装有 docker 的linux,执行以下命令解码音频后再传回来 |
# wechat-backup 导出 html
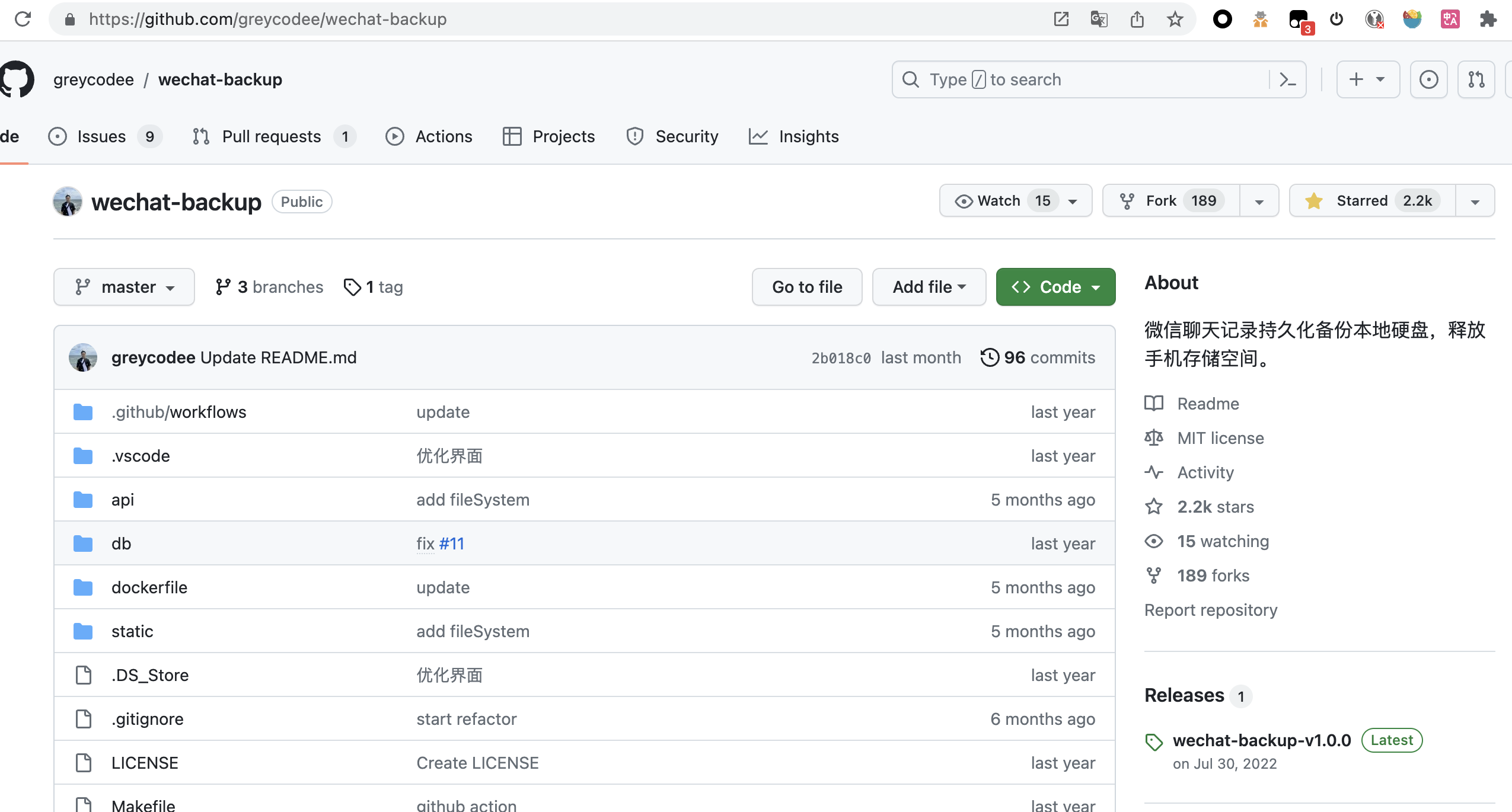
源码位置:https://github.com/greycodee/wechat-backup
修改代码中指向的数据库名和数据库索引表 -> 本地 web 查看聊天记录
-
wechat-backup 是用 go 写出来的,star*2.2k, 效果还是很不错的
![Image]()
-
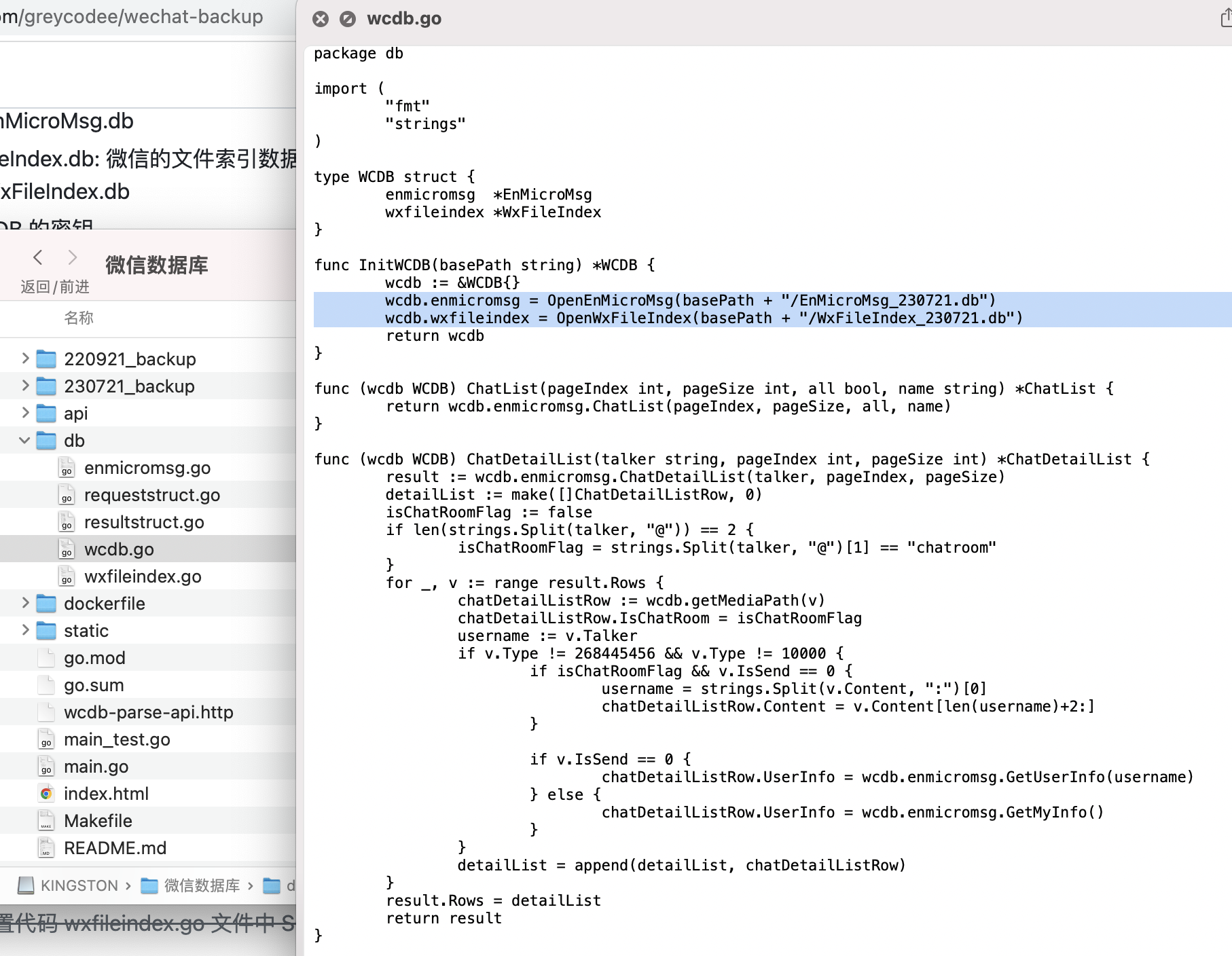
修改 db/wxdb.go 下的数据库名,改为刚才解码导出后的两个数据库
![Image]()
-
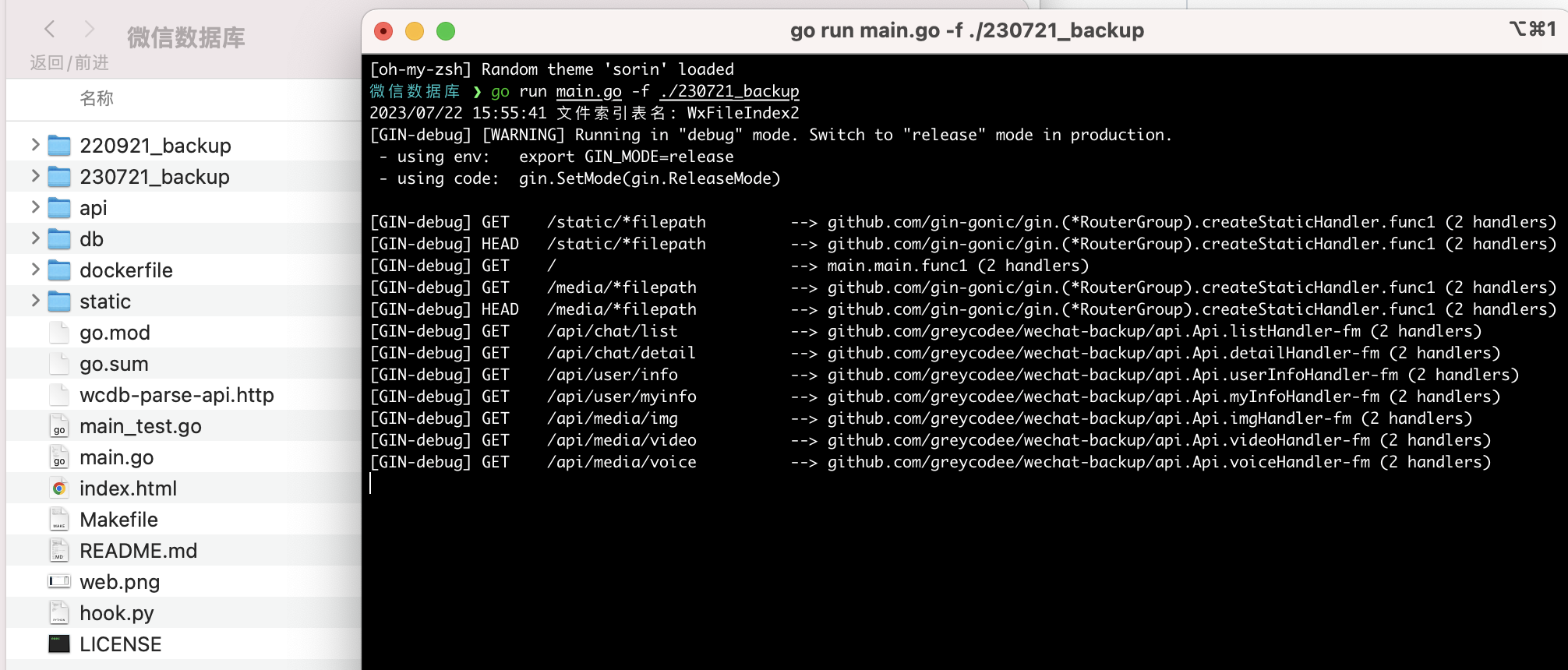
指定数据运行程序
go run main.go -f /Volumes/KINGSTON/微信数据库/230721_backup
![Image]()
-
查看聊天记录
http://127.0.0.1:9999
![Image]()
# wechat-dump 导出 html
源码位置:https://github.com/ppwwyyxx/wechat-dump
- wechat-backup 是用 py 写出来的,star*1.5k, 效果我很喜欢
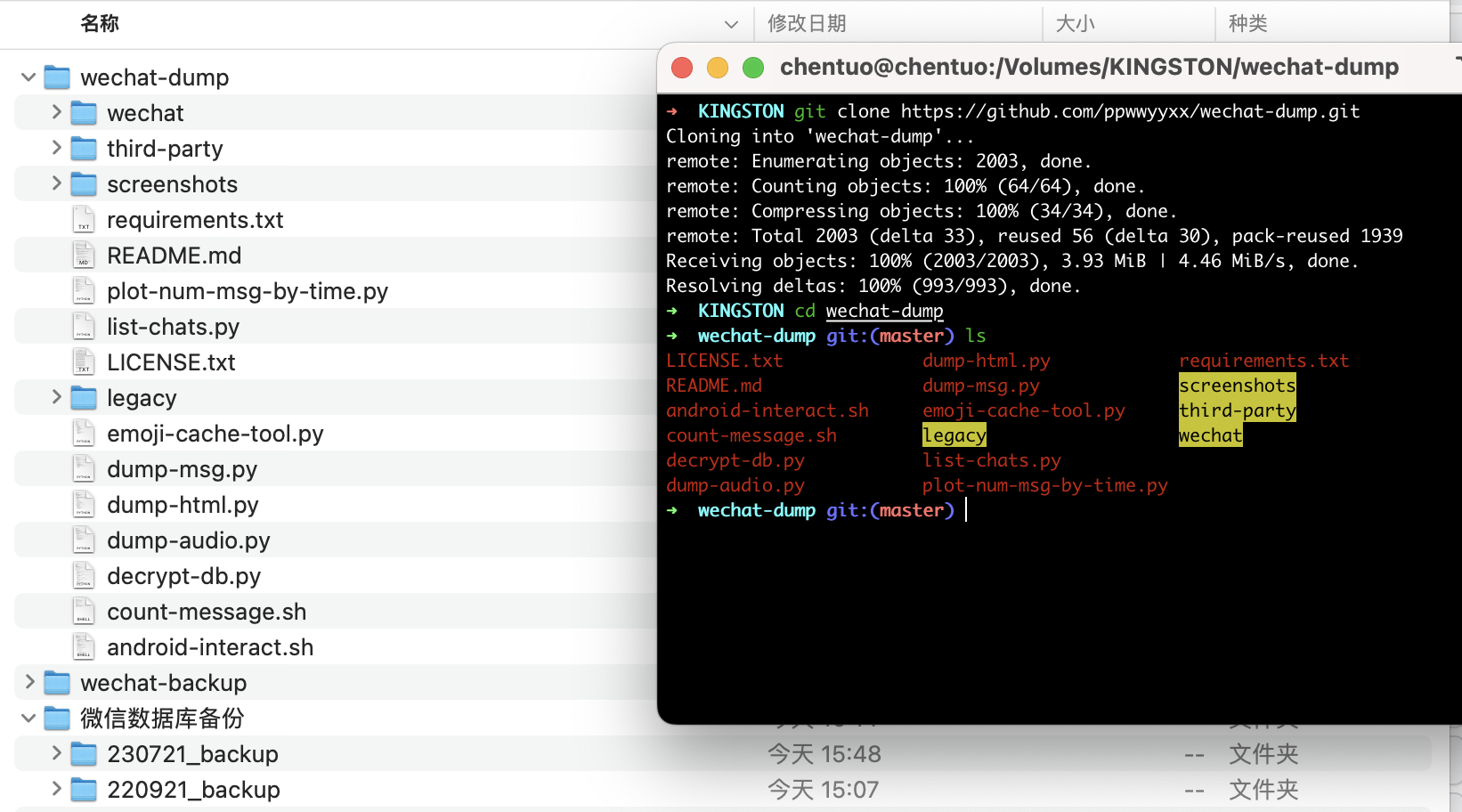
- 克隆项目
git clone https://github.com/ppwwyyxx/wechat-dump.git
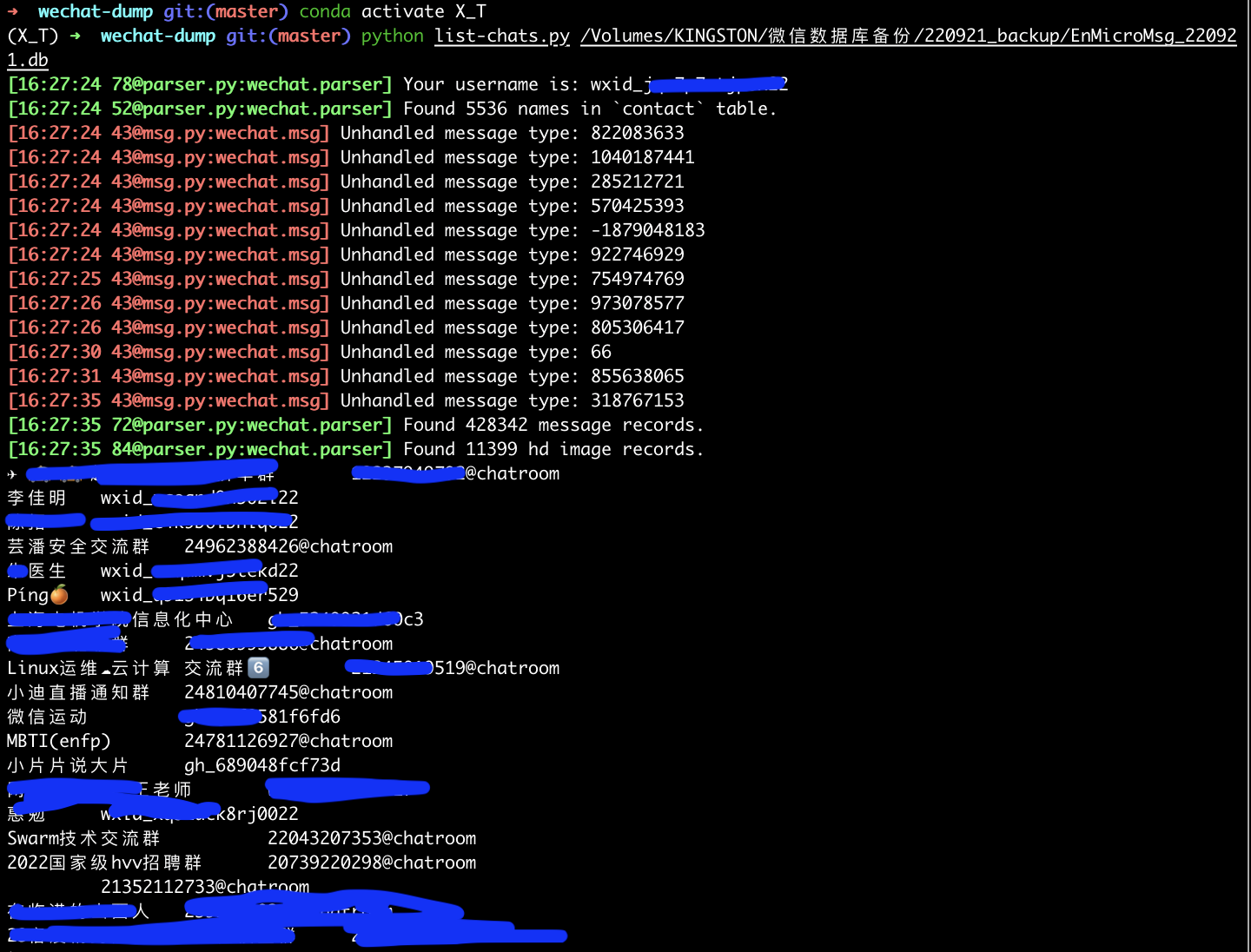
- 列出联系人及其微信号
python list-chats.py /Volumes/KINGSTON/微信数据库备份/220921_backup/EnMicroMsg_220921.db > list_chats_22.txt
- 导出数据库中的聊天记录
python dump-msg.py /Volumes/KINGSTON/微信数据库备份/220921_backup/EnMicroMsg_220921.db res/msg
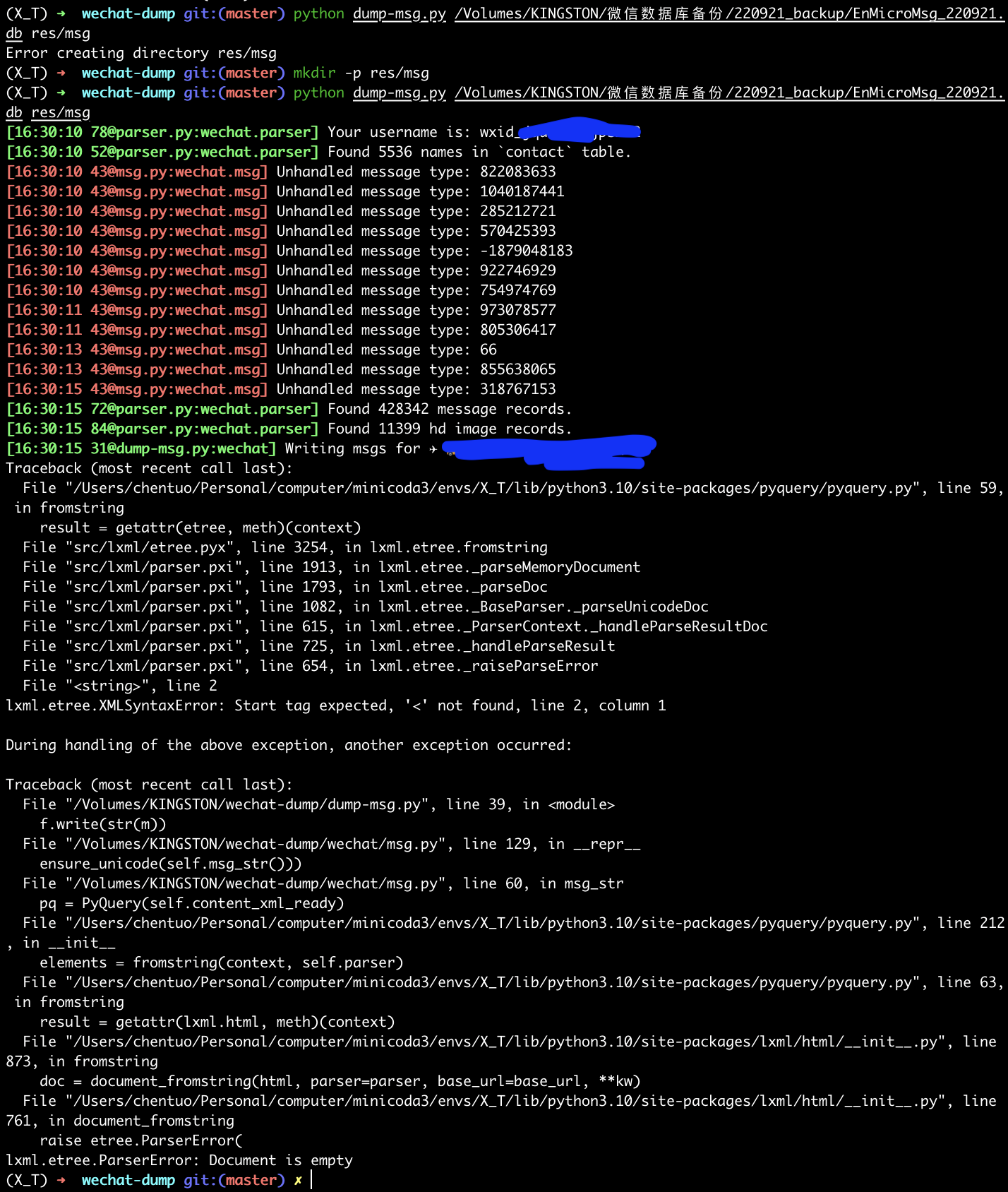
如图,环境问题终于还是来了,不过这个脚本直接加个 try 就可以解决了
- 加个捕获异常可以正常导出聊天的 msg 信息
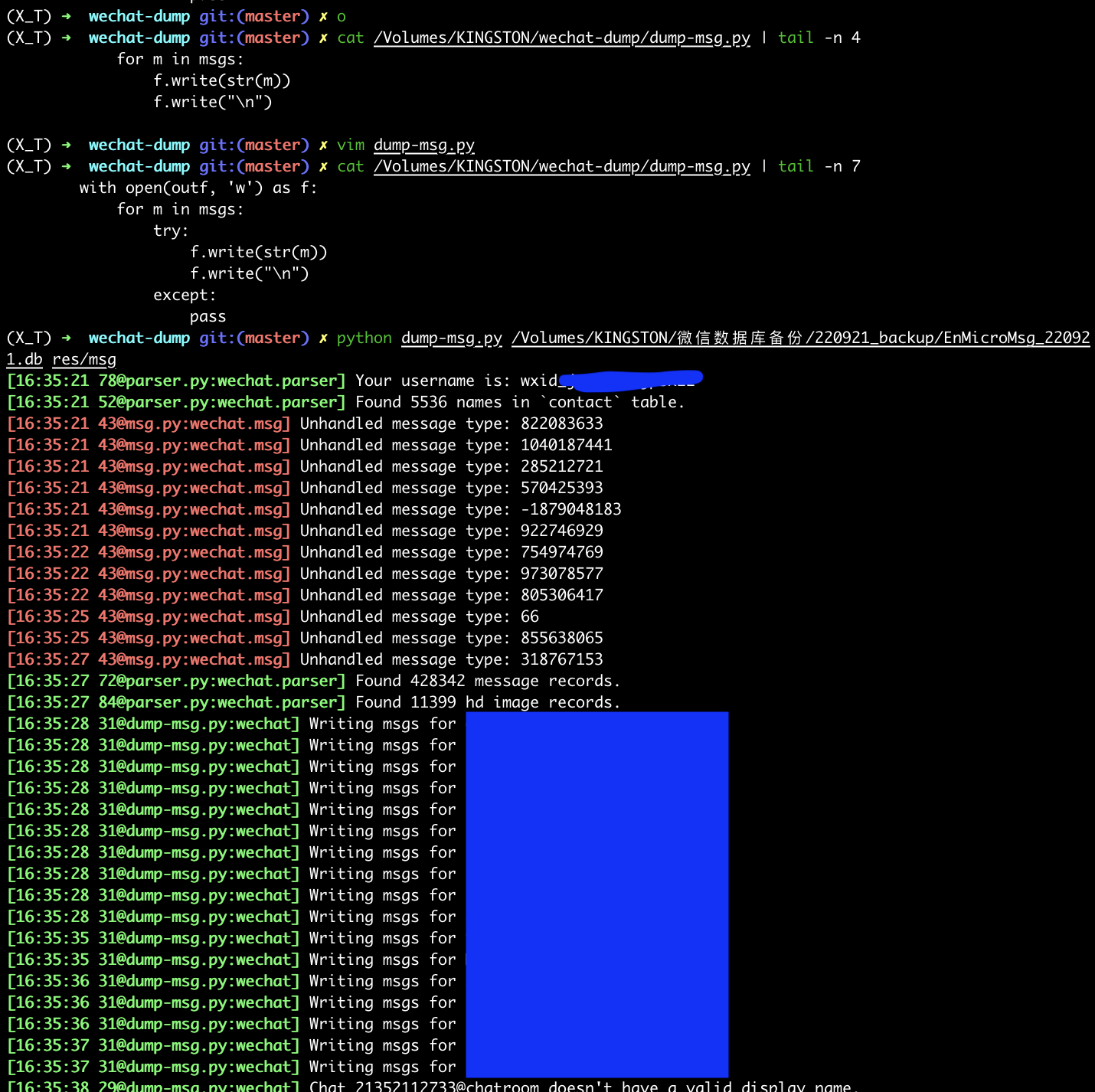
- 可以看到每个人或者每个群的聊天记录的 msg 信息,可据此写写前端
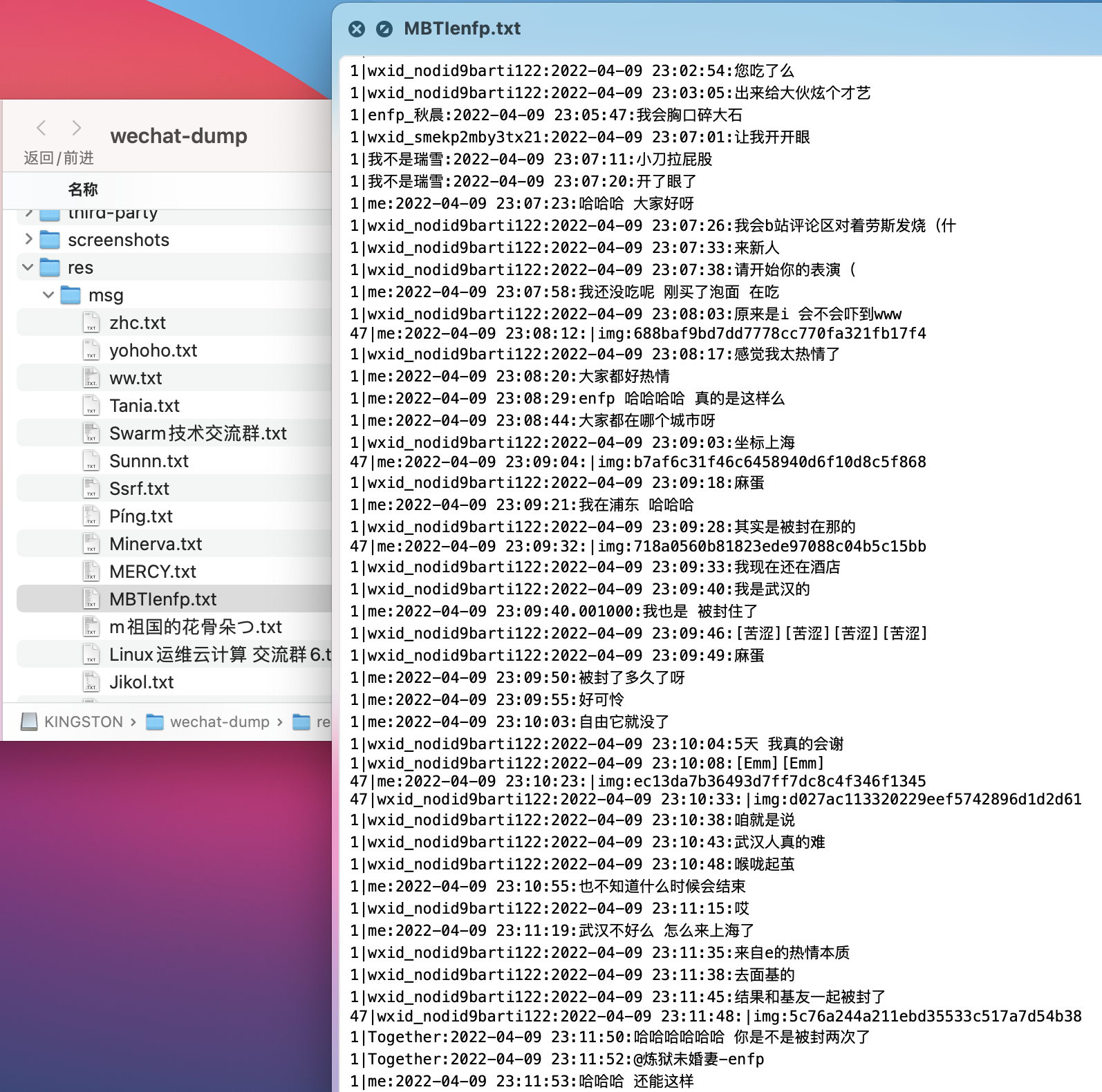
但是接下来将聊天记录导出为 html 的时候,碰到了很多奇怪的问题,自己索性修改了作者提供的源码
# 修改 wechat-dump 源码
源码位置:https://github.com/n1h1l157/wechat-dump
或许在调试的时候还是会遇到些 bug,建议自己 fork 下来断点调试
- 导出为 html
python dump-html.py --db /Volumes/KINGSTON/微信数据库备份/220921_backup/EnMicroMsg_220921.db --res /Volumes/KINGSTON/微信数据库备份/230721_backup --output result/Camile/Camile.html wxid_qxxxxxxx22
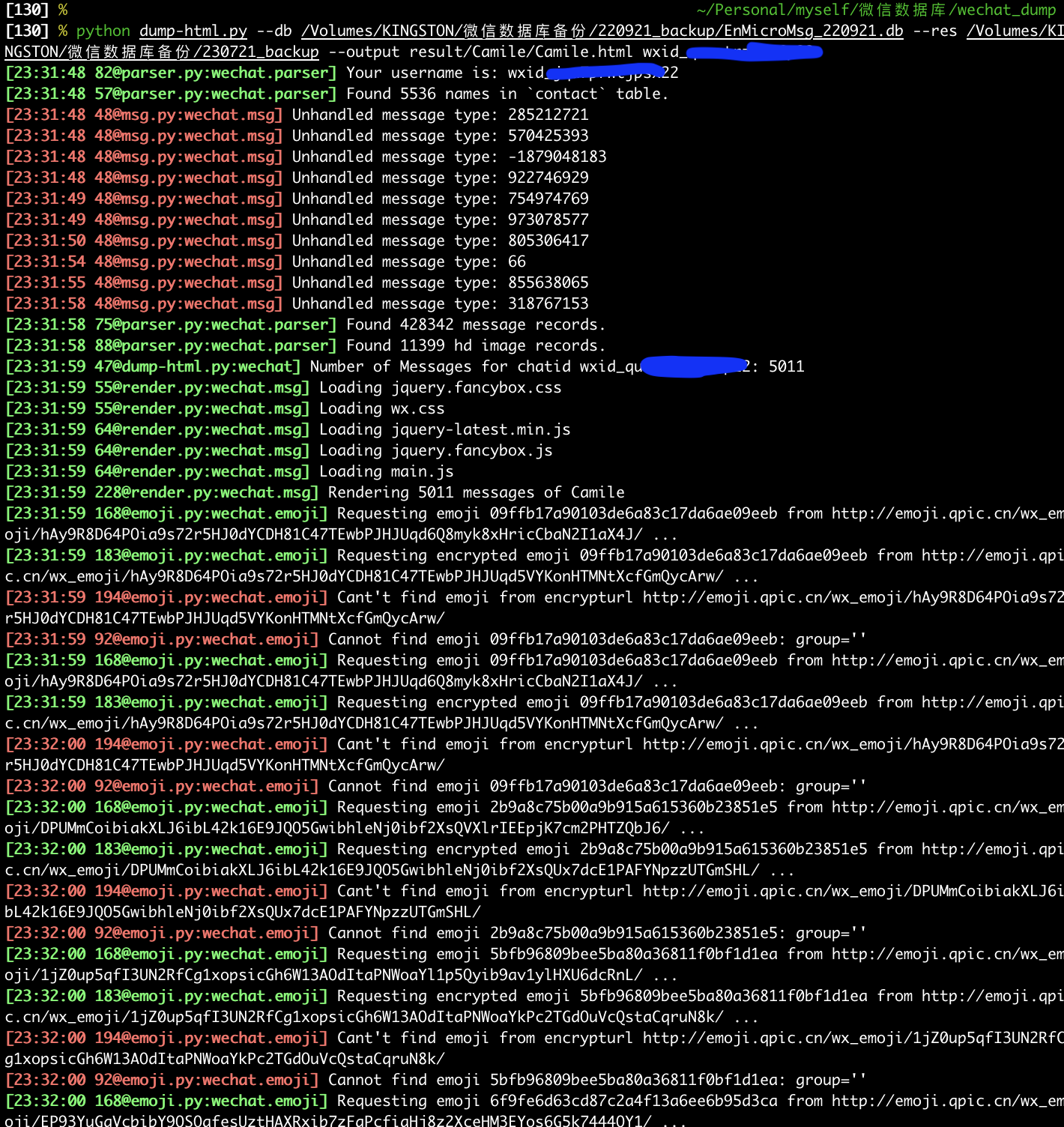
- 导出后的文件如图,html 被分为若干个
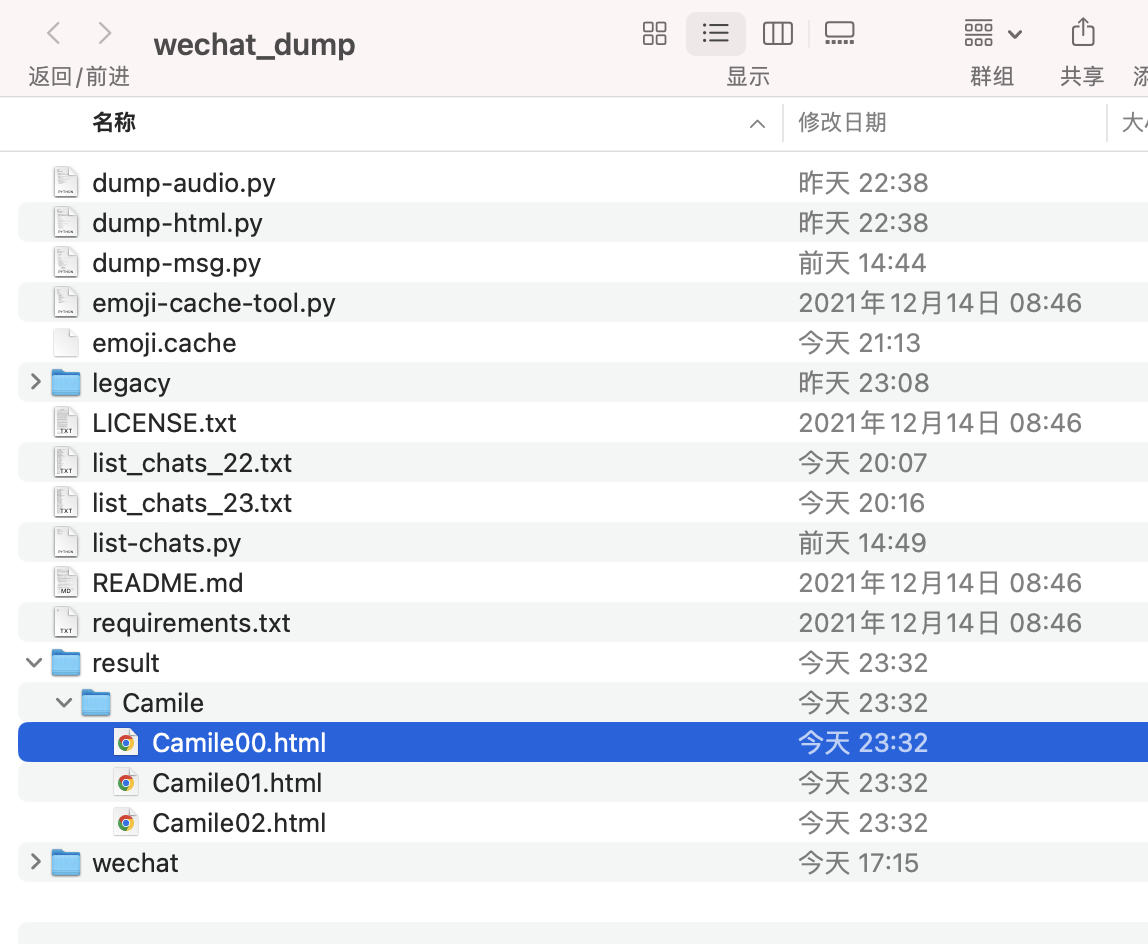
- 可以本地预览这些 html 文件,表情包、图标、音频、视频等都是正常的,除非图片已经丢失
# 导出聊天记录为 pdf
后面做了自定义的一些设置,直接把脚本贴到 github 了,需要自行阅读源码理解
- 按自己喜欢的方式做了一些小改变,将 html 拼接为一个整体的大的 html 文件
python merge_html.py -f /Users/chentuo/Personal/myself/微信数据库/wechat_dump/result/Camile -n Camile.html
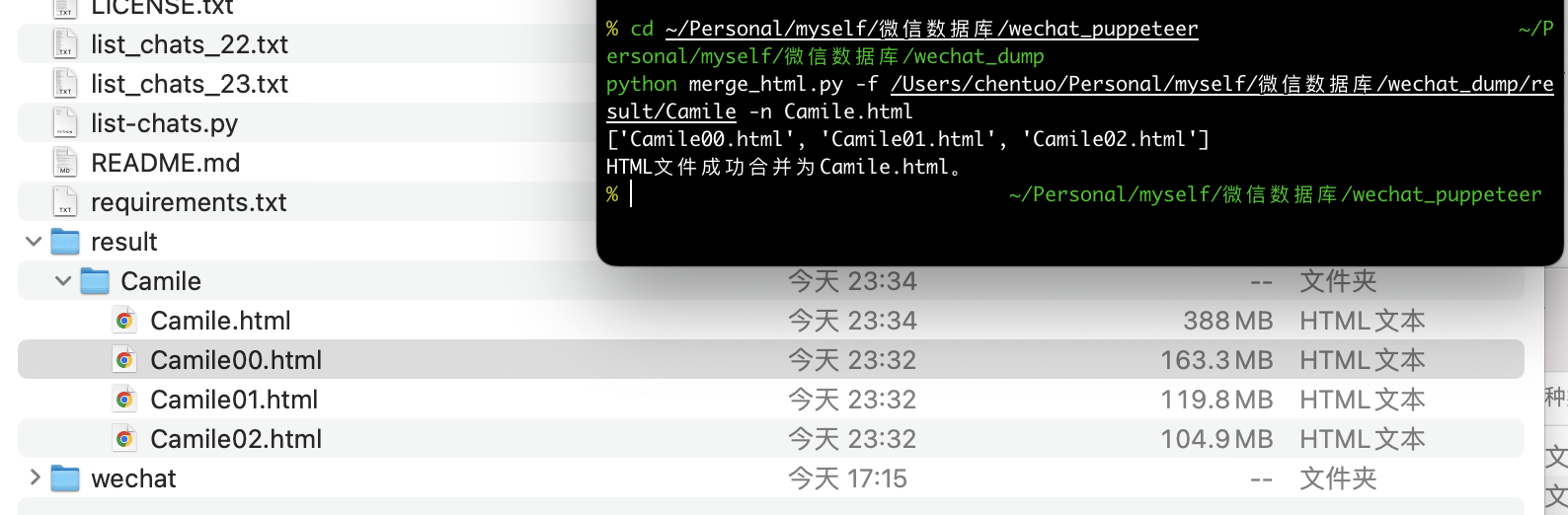
- 对 html 做处理,使得拼接后的 html 文件只保留最顶部的滚动条
python modify_html.py --nickname 'Camile' --input /Users/chentuo/Personal/myself/微信数据库/wechat_dump/result/Camile/Camile.html
30)通过 js 加载 puppeteer,用一个谷歌浏览器的测试版将 html 转为多页的 pdf
参考项目:https://github.com/puppeteer/puppeteer
node convert_html_to_pdf.js -f 'Camile' -n 20 -e '~/.cache/puppeteer/chrome/mac_arm-114.0.5735.133/chrome-mac-arm64/Google Chrome for Testing.app/Contents/MacOS/Google Chrome for Testing'
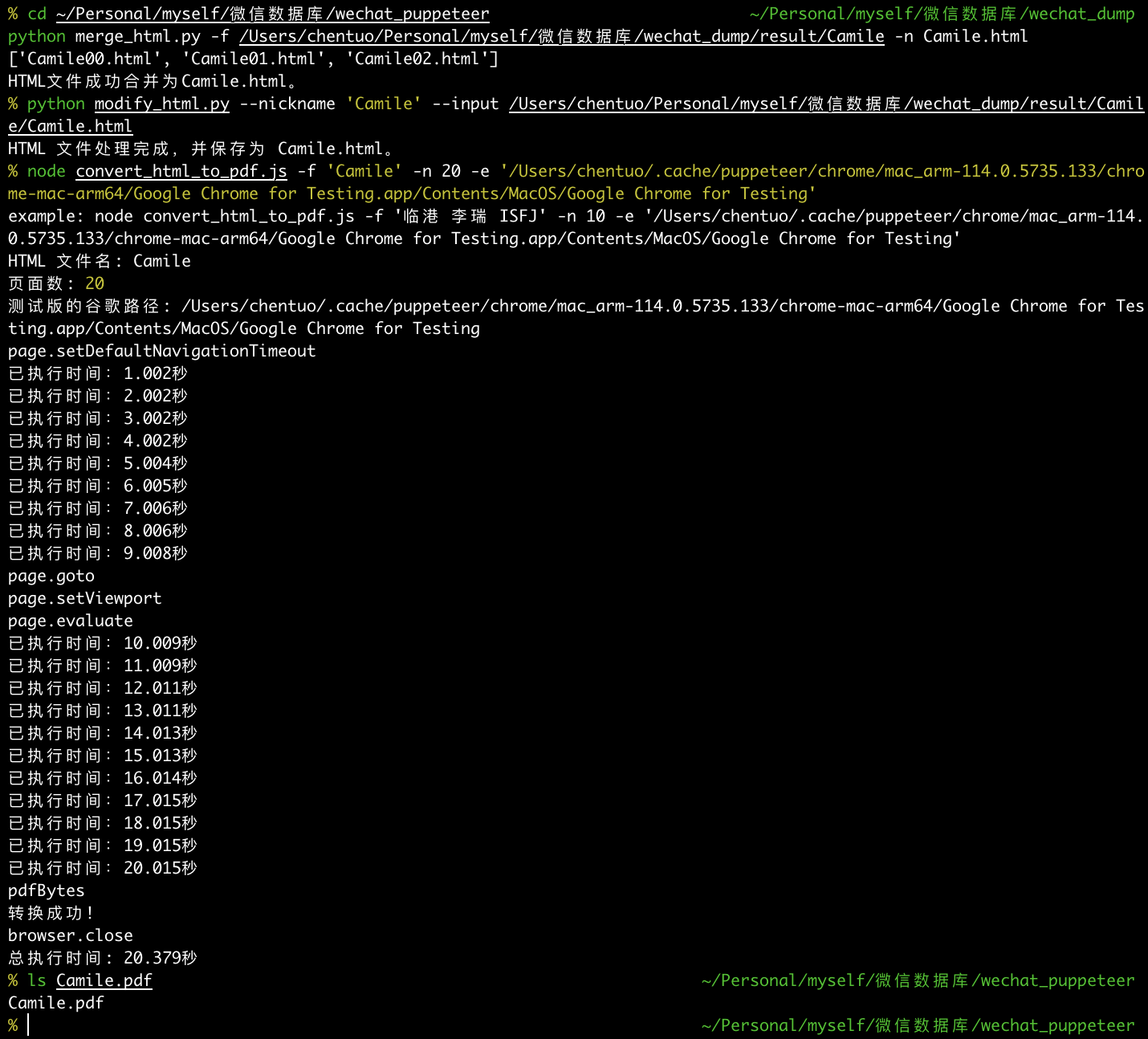
- 最后聊天记录保存成了本地的 pdf 文件
大功告成,结束。